단순 선형 회귀분석 (Simple Linear Regression) 결과를 이해하고,
검정 곡선 (Calibration Curve) 검증에 필요한 내용을 알아보자.
표준물질 측정결과를 바탕으로 농도와 장비의 상관성 수식을 회귀분석을 통해서 확인할 수 있다.
많은 실험 결과에서 직선의 상관성이 나타나며 일차 방정식 (y = ax + b) 수식이 회귀분석으로 확인된다.
회귀분석으로 확인된 검정곡선의 수식은 시료의 농도를 계산할 때 사용되므로
시료 농도 계산에 오류가 발생되지 않도록 검증이 꼭 필요하다.
엑셀에는 단순 선형 회귀분석 결과를 쉽게 얻을 수 있다.
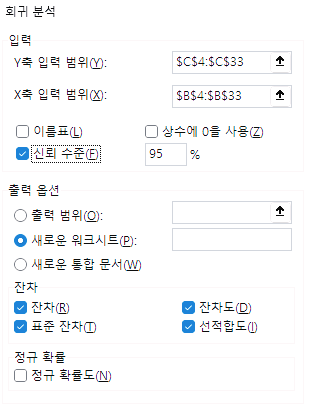
"데이터 > 분석 > 데이터 분석" 을 선택하면 다음과 같은 창이 나타나고,

해당 메뉴에는 회귀분석이 포함되어 있다.
회귀분석을 선택하면 새창이 나타나고, 데이터를 입력하도록 되어있다.
아래 그림과 같이 실험 농도 (x)와 측정 결과 (y)의 범위를 지정하고,
'잔차' 에 세부 항목들을 모두 체크하면 검정곡선 검증에 필요한 정보들을 얻을 수 있다.
선택한 데이터 (X, Y)를 기반으로 회귀분석을 진행하면 다음과 같은 결과를 얻을 수 있다.

회귀분석 결과들이 어떻게 계산되는지 알아보면, 결과 내용을 이해하는데 도움이 된다.
회귀분석 통계량, 분산 분석, 잔차 출력으로 분류된 결과들의 계산 내용을 알아보자.
# 분산 분석
* 적절한 설명을 위해서 결과 순서와 다르게 기술됩니다. *
- 잔차 (Residual)
- 자유도 ($df_{residual}$)
$$df_{residual}= n - p = n - 2$$
$n$ 은 측정치의 수를 나타내고,
$p$ 는 "독립변수 + 상수"로 적용된다.
직선의 검정곡선에서는 독립변수 1, 상수 1개 이므로 $p=2$ 로 계산된다. - 제곱 합 ($SSE$ : Sum of Squares Error)
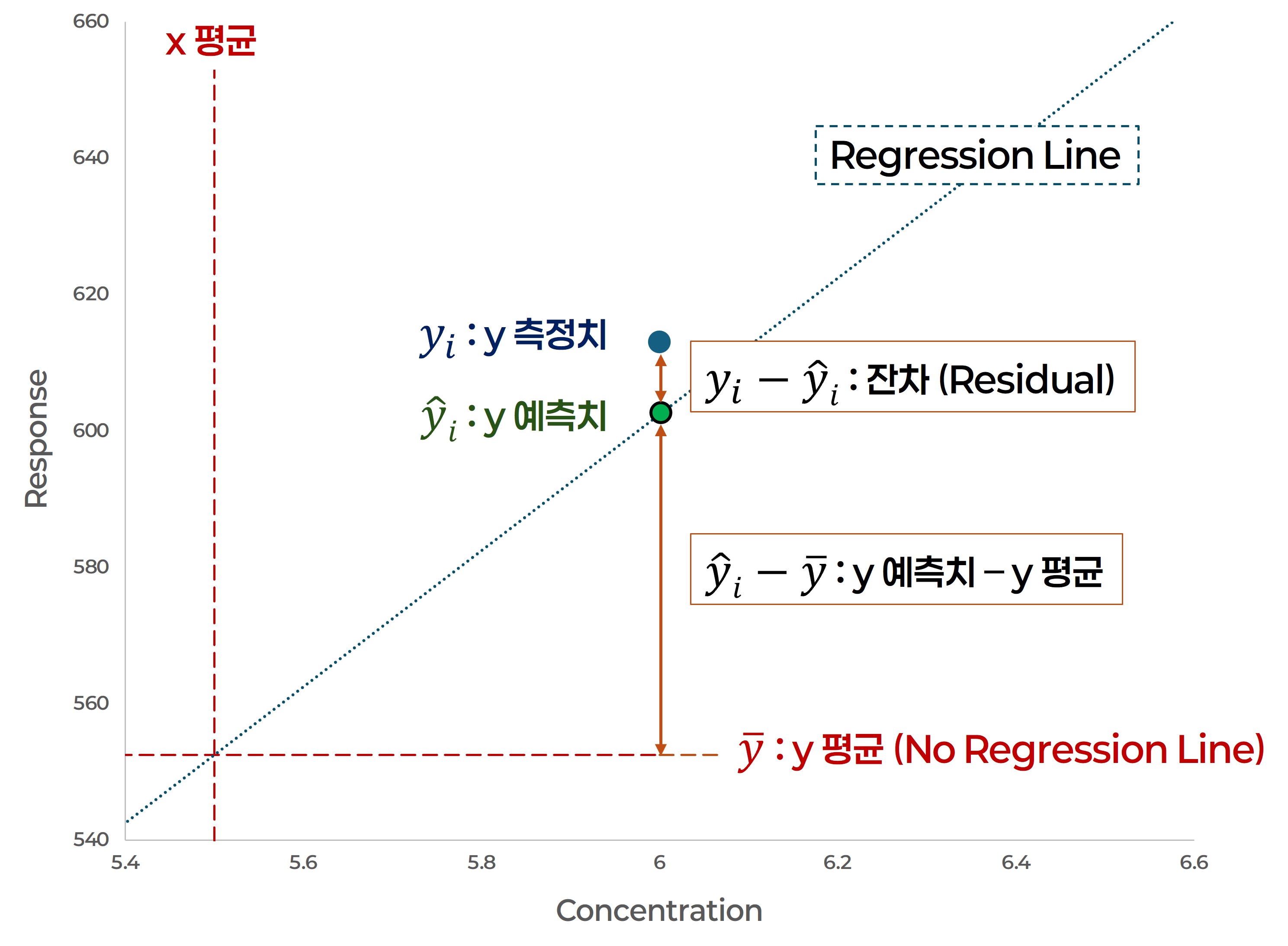
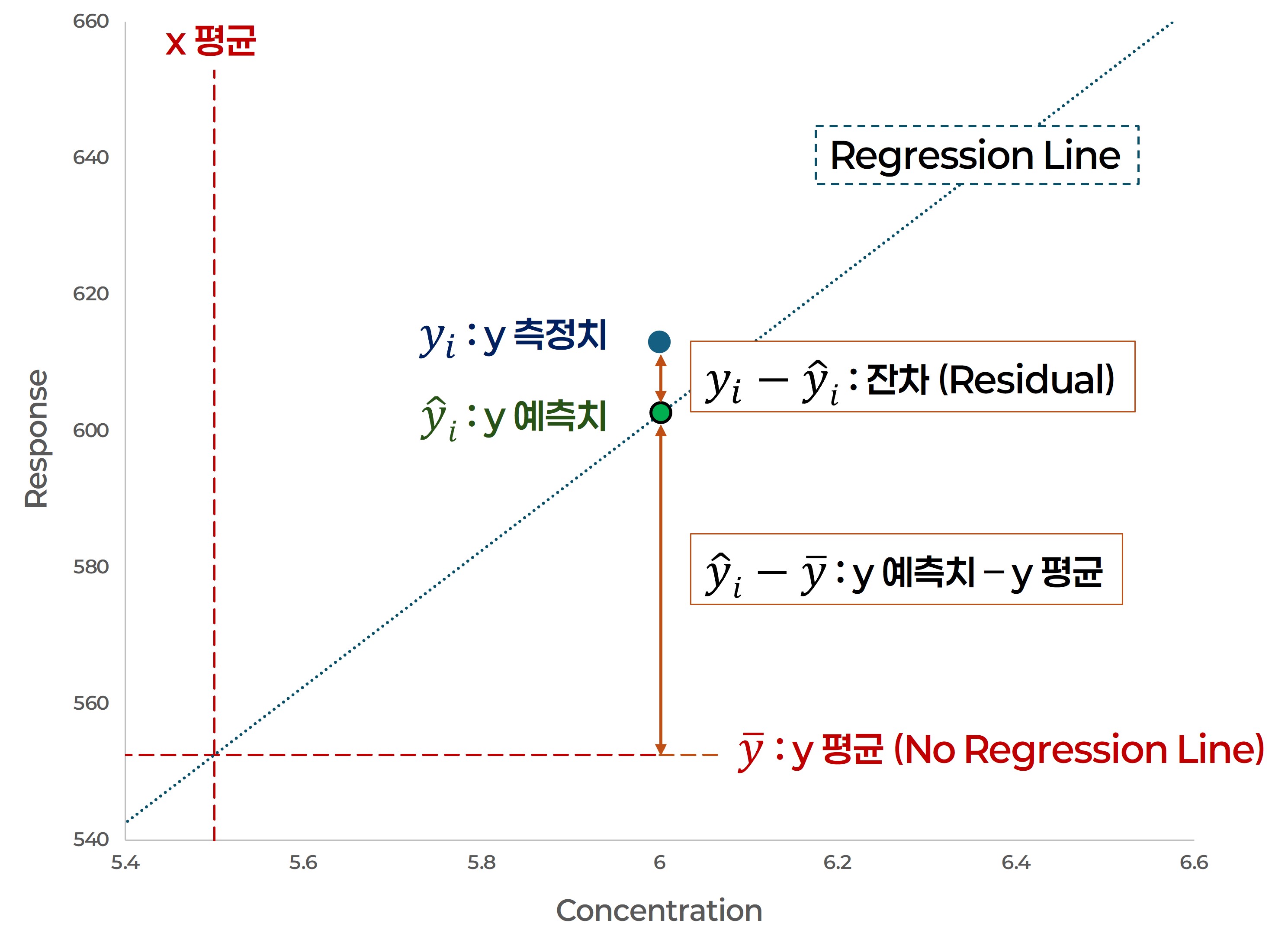
$$SSE = \sum_{i=1}^{n} (y_i - \hat{y}_i)^2$$
잔차 (residual) 는 y 값의 측정치와 예측치의 차이를 말하며,
제곱합 ($SSE$) 은 모든 잔차를 제곱해서 합한 값이다.
회귀분석 수식과 측정치의 전체 오차를 나타내는 값으로
모든 잔차가 최소화 되도록 회귀분석 수식을 추정하는데 사용된다.
해당 항목은 "잔차 제곱합 (RSS: Residual of Sum Squares)" 이라고도 한다. - 제곱 평균 ($MSE$ : Mean of Squares Error)
$$MSE = \dfrac{SSE}{df_{residual}} = \dfrac{SSE}{(n-2)}$$
잔차의 제곱 합은 전체 잔차를 나타내는 값으로
개별 $y_i$ 값에서 나타나는 잔차를 확인하기 위해서 계산한 값이다.
- 자유도 ($df_{residual}$)
- 회귀 (Regression)
- 자유도 ($df_{regression}$) : 독립변수 (x) 수
농도와 측정치의 상관성에서 x (농도)는 단일 물질의 농도이므로 설정 값은 1이다.
2개 물질 (x1, x2) 농도의 상관성을 확인한다면, 자유도 설정 값은 2이다. - 제곱 합 ($SSR$: Sum of Squares Regression)
$$SSR = \sum_{i=1}^{n} (\hat{y}_i - \bar{y})^2$$
$\hat{y}_i$는 x 값에 대응하는 회귀분석 수식으로 계산된 y 값이고,
$\bar{y}$는 회귀분석에서 비상관성을 나타내는 상태로 y 값의 평균이다.
$SSR$ 제곱합은 회귀분석의 $y_i$ 값과 $y$ 값의 차이를 제곱해서 모두 합한 값이다.
회귀분석 수식과 데이터의 관계를 확인하기 위해서 사용된다.
- 자유도 ($df_{regression}$) : 독립변수 (x) 수
-
- 제곱 평균 ($MSR$)
$$ MSR = \dfrac{SSR}{ df_{regression}} = \dfrac{SSR}{1}$$
$MSR$은 제곱합을 평균한 것으로
검정곡선에서는 독립변수 x가 1개 이므로 $SSR$ 값과 동일하다. - F 비 ($F\ ratio$)
$$F\ ratio = \dfrac{MSR}{MSE}$$
회귀의 제곱 평균 ($MSR$)과 잔차의 제곱 평균 ($MSE$)의 비율 값으로
잔차의 평균적인 차이에 비해 회귀분석 예측값의 차이를 비율로 확인한 것이다.
측정 데이터의 상관성이 없다면,
회귀분석 수식은 y 평균 라인과 비슷해지고
잔차 제곱 평균과 회귀 제곱 평균은 차이가 없어지고 비율은 1에 가깝게 된다.
측정 데이터의 상관성이 나타나면,
회귀 제곱 평균이 잔차 제곱 평균보다 큰 차이를 보이고 비율은 1보다 증가하게 된다.
F 비는 분산분석의 검정통계량으로 잔차의 분산에 비해 예측값의 분산과 차이가 있는지 확인한 것으로
검정곡선인 경우에는 F 비율 값이 1보다 큰 것이 적합하다. - 유의한 F (Significance F) : 분산분석 유의확률 (p-value)
F비 값이 1인 상태를 가정해서 확률로 나타낸 값이다.
즉, 회귀 제곱 평균과 잔차 제곱 평균의 분산이 동일하다는 가정으로 확률을 계산한 것이다.
유의한 F (p-value) 값이 1 이면, 두 항목의 분산 값이 동일할 확률이 100% 이고,
유의한 F (p-value) 값이 0 이면, 두 항목의 분산 값이 동일할 확률이 0% 이다.
통계적으로 유의한 차이점을 구분하는 기준은 95% 구간이다.
분산이 동일할 확률이 95% 범위 안인 상태는 p-value 값이 0.05 이상으로 나타나고,
분산이 동일할 확률이 95% 범위 밖인 상태는 p-value 값이 0.05 이하로 나타난다.
유의한 F를 확인하는 이유는 F 비가 1보다 큰 값으로 계산되어도 명확한 차이가 나타나지 않을 수 있다.
그래서 통계적으로 의미있는 차이를 확인하기 위해서 유의한 F (p-value)를 확인한다.
검정곡선에서 잔차가 적은 회귀분석 수식이 농도계산 오차가 적게 발생하므로
F 비는 1보다 크게 나타나고, 유의한 F (p-value) 값도 0.05 이하로 나타나는 것이 적합하다.
- 제곱 평균 ($MSR$)
- 계 (Total)
- 자유도 ($df_{total}$)
$$ df_{total} = n - 1$$
$n$ 은 측정치의 수를 나타내고, 자유도는 $ n - 1$ 로 계산된다. - 제곱합 ($SSTO$)
$$ SSTO=\sum_{i=1}^{n} (y_i - \bar{y})^2 = SSR + SSE $$
$SSTO$ 는 회귀 제곱합 ($SSR$) 과 잔차 제곱합 ($SSE$) 의 합으로
측정치 ($y_i$) 와 측정치 평균 ($\bar{y}$) 의 차이를 제곱해서 모두 합한 값이다.
- 자유도 ($df_{total}$)
- 기울기 (X variable 1)
- 계수 (Coefficients, $b_1$)
$$b_1 = \dfrac{\sum_{i=1}^{n}(x_i-\bar{x})(y_i-\bar{y})}{\sum_{i=1}^{n}(x_i-\bar{x})^2} = \dfrac{n\sum(x_i y_i) - \sum x_i \sum y_i}{n\sum(x_i^2)-(\sum x_i)^2}$$
회귀분석에서 추정된 기울기 값으로
데이터 x, y 간의 공분산과 x의 분산 비율이다.
$$b_1 = \dfrac {Covariance \ (x,y)}{Variance\ (x)}$$
즉, x 변화량을 기준으로 y 변동량을 나타낸 값이다.
검정곡선에서 기울기는 농도 (x) 1이 변경할 때, 측정치 (y) 의 변화량을 나타낸다. - 표준오차 (Standard Error, $SE(b_1)$)
$$ SE(b_1) = SE(e) \cdot \sqrt{\dfrac{1}{n} +\dfrac{\bar{x}^2}{\sum_{i=1}^{n} (x_i - \bar{x})^2}}$$
⋅ $SE(e)=\sqrt{MSE}$ : 잔차의 표준오차
⋅ $\bar{x}$ : 독립 변수 x의 평균
⋅ $\sum_{i=1}^{n} (x_i - \bar{x})^2$ : 독립변수 x의 변동성 (분산) - t 통계량 (t Stat)
$$ t = \dfrac{SE(b_1)}{b_1} $$
t-검증 (평균 비교 테스트) 에 필요한 통계량으로 표준오차를 계수로 나눈 값이다.
비교 테스트 내용은 회귀분석으로 추정된 기울기 값이 "0" 과 차이가 있는지 확인하기 위한 것이다.
회귀분석의 상관성 유무를 확인하기 위한 통계량 값이다. - P-값 (p-value)
t-통계량의 유의성을 확인하기 위한 값으로
회귀분석으로 추정된 기울기 값이 0과 유의한 차이가 있는지 확인하기 위해서 사용된다.
기울기가 0 인 경우를 가정해서 확률을 계산한 값으로
기울기가 0으로 동일할 확률이 95% 범위 안인 상태는 p-value 값이 0.05 이상으로 나타나고,
기울기가 0으로 동일할 확률이 95% 범위 밖인 상태는 p-value 값이 0.05 이하로 나타난다.
t 통계량의 유의성 (p-value)을 확인하는 이유는 기울기 값이 0이 아닌 값으로 나타나도
유의한 상관성 기울기인지 확인하기 위해서 사용된다.
검정곡선은 농도에 따라서 측정치 변화가 뚜렷한 차이를 나타나야 하므로
기울기 값은 0보다 크게 나타나고, p-value 값도 0.05 이하로 나타나는 것이 적합하다. - 95% 신뢰구간 (CI: Confidence Interval)
$$ 95\% \ CI = b_1 \pm t_{α/2, \ df} \times SE(b_1)$$- 하위 95% (Lower 95%) $=b_1 - t_{α/2, \ df} \times SE(b_1)$
- 상위 95% (Upper 95%) $=b_1 + t_{α/2, \ df} \times SE(b_1)$
⋅ $b_1$ : 기울기 계수
⋅ $SE(b_1)$ : 기울기의 표준오차
⋅ $t_{α/2,\ df}$ : t-분포에서 해당 자유도와 신뢰구간에 해당하는 임계값
엑셀에서는 95% 신뢰구간 및 양측검증에 해당하는 함수는 계산은
" = T.INV.2T(0.05, n - 2) " 함수를 이용해서 계산할 수 있다.
자유도는 n - k - 1로 적용되며, 독립변수 (k)가 1개 이므로 n - 2로 계산된다.
- 계수 (Coefficients, $b_1$)
- 절편 (Intercept)
- 계수 (Coefficients,$b_0$)
$$b_0 = \bar{y} - b_1 \times \bar{x} $$
회귀분석에서 추정된 기울기 값과 x 평균, y 평균을 이용해서 일차 방정식의 절편을 계산한다.
검정곡선에서 절편은 절대적으로 0을 나타내지 않는다.
실험에 따라서 0 또는 일정한 값을 나타내므로
회귀분석에서 추정된 절편을 농도 계산에 적용해야 농도 계산에 오차를 줄일 수 있다. - 표준오차 (Standard Error, $SE(b_0)$)
$$ SE(b_0) = SE(e) \cdot \sqrt{\dfrac{1}{\sum_{i=1}^{n} (x_i - \bar{x})^2}}$$
⋅ $SE(e)=\sqrt{MSE}$ : 잔차의 표준오차
⋅ $\bar{x}$ : 독립 변수 x의 평균
⋅ $\sum_{i=1}^{n} (x_i - \bar{x})^2$ : 독립변수 x의 변동성 (분산) - t 통계량 (t Stat)
$$ t = \dfrac{SE(b_0)}{b_0} $$
t-검증 (평균 비교 테스트) 에 필요한 통계량으로 표준오차를 계수로 나눈 값이다.
비교 테스트 내용은 회귀분석으로 추정된 절편 값이 "0" 과 차이가 있는지 확인하기 위한 것이다. - P-값 (p-value)
t-통계량의 유의성을 확인하기 위한 값으로
회귀분석으로 추정된 절편 값이 0과 유의한 차이가 있는지 확인하기 위해서 사용된다.
절편이 0 인 경우를 가정해서 확률을 계산한 값으로
절편이 0으로 동일할 확률이 95% 범위 안인 상태는 p-value 값이 0.05 이상으로 나타나고,
절편이 0으로 동일할 확률이 95% 범위 밖인 상태는 p-value 값이 0.05 이하로 나타난다.
t 통계량의 유의성 (p-value)을 확인하는 이유는 절편 값이 0과 차이가 있는지 확인위한 것이다.
검정곡선의 절편은 실험에 따라 다르게 나타나므로 0과 유의한 차이는 중요하지 않다. - 95% 신뢰구간 (CI: Confidence Interval)
$$ 95\% \ CI = b_0 \pm t_{α/2,\ df} \times SE(b_0) $$- 하위 95% (Lower 95%) $=b_0 - t_{α/2,\ df} \times SE(b_0) $
- 상위 95% (Upper 95%) $=b_0 + t_{α/2, \ df} \times SE(b_0)$
⋅ $b_0$ : 절편 계수
⋅ $SE(b_0)$ : 절편의 표준오차
⋅ $t_{α/2, df}$ : t-분포에서 해당 자유도와 신뢰구간에 해당하는 임계값
엑셀에서는 95% 신뢰구간 및 양측검증에 해당하는 함수는 계산은
" = T.INV.2T(0.05, n - 2) " 함수를 이용해서 계산할 수 있다.
자유도는 n - k - 1로 적용되며, 독립변수 (k)가 1개 이므로 n - 2로 계산된다.
- 계수 (Coefficients,$b_0$)
# 회귀분석 통계량
- 다중 상관계수 ($R$)
$$R= \dfrac{\sum_{i=1}^{n}(x_i - \bar{x})(y_i - \bar{y})}{ \sqrt{\sum_{i=1}^{n}(x_i - \bar{x})^2 \times \sum_{i=1}^{n}(y_i - \bar{y})^2 } }$$
상관계수는 데이터 (측정치)와 회귀분석 수식의 상관성을 나타내고,
데이터와 수식의 오차가 적으면 상관계수 값은 1에 근접하고, 상관성이 없으면 0에 근접한다.
상관계수는 양의 상관성을 가지면 + 값을 나타내고, 음의 상관성을 가지면 - 값을 나타낸다. - 결정계수 ($R^2$)
$$R^2= R \times R =\dfrac{SSR}{SSTO} = 1 - \left(\dfrac{SSE}{SSTO}\right)$$
결정계수는 상관계수를 제곱한 값으로 회귀 제곱합 ($SSR$)을 전체 제곱합 ($SSTO$)을 나눠도 계산할 수 있다.
회귀 제곱합이 전체 제곱합에 근접하면 1에 가까운 값을 가지고, 차이가 증가하면 0에 가까운 값을 나타낸다.
즉, 잔차 제곱합이 적을 수록 1에 가까운 값을 나타내는 것이다.
검정곡선에서 잔차가 적은 회귀분석 수식일수록 농도 계산에 오차가 적다. - 조정된 결정계수 ($Adjusted \ R^2$)
$$Adjusted \ R^2 = 1-\dfrac{SSE/(n-k-1)}{SSTO/(n-1)}$$
k는 독립변수의 수를 나타내며, 일차방정식에서는 x가 1개 이다.
관측수와 독립변수 x 의 개수가 증가하면 상관계수가 1에 가까워지는 현상이 나타난다.
관측수와 독립변수의 영향이 배제된 상관성을 확인한 결과로 일차방정식에서는 필요하지 않다. - 표준오차 (Standard Error, $SE(e)$)
$$ SE(e) = \sqrt{\frac{SSE}{n-2}} = \sqrt{MSE}$$
모든 잔차의 표준편차로 잔차 값의 변동 범위를 나타낸다. - 관측수 (Observation, $n$)
x, y 쌍으로 조합된 데이터 수
# 잔차 출력
- 관측수 (Observation, $n$)
x, y 쌍으로 조합된 데이터 수 - Y 예측치 (Predicted Y, $\hat{y}_i$)
$$ \hat{y}_i = b_1 \times x_i + b_0$$
측정치 x 를 회귀분석 수식에 대입해서 계산된 y 값이다.
Y 예측치는 잔차 계산에 사용된다. - 잔차 (Residual, $e_i$)
$$ e_i = y_i - \hat{y}_i $$
데이터 y의 측정치와 예측치의 차이로 회귀분석 수식의 y 값 오차이다.
개별 데이터의 잔차는 회귀분석 수식의 오류를 확인하는데 사용되며
수식을 기준으로 무작위 오차가 발생되어 나타나면 정상적인 결과이다.
무작위 오차를 확인하기 위해서 잔차도를 작성해서 확인한다.
잔차도의 자세한 내용은 링크 내용을 참고 바랍니다. - 표준 잔차 (Standard Residuals, $r_i$)
$$ r_i = \dfrac{e_i}{SE(e_i)} $$
⋅ $r_i$ : $i$ 번째 데이터의 표준 잔차
⋅ $e_i$ : $i$ 번째 데이터의 잔차
⋅ $SE(e_i)$ : $i$ 번째 데이터의 잔차의 표준오차
개별 잔차의 표준오차는 아래 수식으로 계산된다.
$SE(e_i) = SE(e) \times \sqrt{1-h_i}$
전체 잔차의 표준오차를 레버리지($h_i$)를 적용해서 계산한다.
레버리지는 x 값의 평균에 벗어난 정도를 수치로 나타낸 것으로
회귀분석 결과에 영향을 미치는 정도이다.
개별 레버리지 값은 아래 행렬로 계산된다.
$h_i = X_i(X^TX)^{-1}X^T_i$
엑셀에서는 개별 레버리지 값을 적용해서 계산하지 않고
개별 레버리지의 평균을 사용해서 동일하게 계산되었다.
검정곡선에서 표준잔차 내용은 측정치의 벗어난 정도를 나타내고 있어서
측정치의 이상치(outlier) 값을 확인하기 위해서 사용된다.
표준잔차는 0을 기준으로 표준편차 1인 값으로 잔차를 변환한 것으로
표준잔차 값이 2 이상으로 벗어난 경우라면 잠재적 이상치로 분류할 수 있다.
검정곡선 검증에는 상관계수 또는 결정계수, y-절편, 기울기 내용을 기본적으로 검토한다.
회귀분석 결과들은 상황에 따라서 구분해서 사용된다.
- 회귀분석의 수식 검증:
결정계수, 절편, 기울기, 농도 측정치와 예측치의 오차 (x 축 오차), 잔차 (y 축 오차) - 검정곡선의 재현성 검증:
결정계수, 잔차 제곱합, 절편, 기울기
그 이외에 추가적으로 회귀분석 결과들은 검토하면
검정곡선에 문제점을 파악하는데 도움을 받을 수 있다.
검정곡선 검증에 필요한 회귀분석 결과들이 어떻게 작성되었는지 확인하였다.
자세한 계산 내용을 첨부된 엑셀 파일에서 확인할 수 있다.
'기기분석 데이터' 카테고리의 다른 글
| [Excel] 회귀분석 (Regression) - 이차방정식 (Quadratic Equation) (0) | 2024.10.21 |
|---|---|
| 검정곡선 (Calibration Curve) 농도 설정과 반복 측정 (2) | 2024.09.23 |
| 검정 곡선 (Calibration Curve) 평가와 가중치 (Weighting) 적용 예시 (2) | 2024.01.08 |
| [Excel] 검정 곡선 (calibration Curve) 평가 : 등분산성 (Homoscedasticity) (0) | 2023.12.31 |
| [Excel] 검정 곡선 (Calibration Curve) 평가 : 잔차도 (Residual Plot) (0) | 2023.12.26 |



